Summary
A variation of the D(N)MTS task allowing greater efficiency of testing with long delays.
About the task
This task is a variant of the normal D(N)MTS task. Suppose you want to test many long delays (e.g. 5 minutes, 10 minutes, and 15 minutes). In the conventional task, in which SAMPLE and CHOICE phases are paired, this would be slow:
SAMPLE 1 ... CHOICE 1 (5 minutes plus response times)
SAMPLE 2 ... CHOICE 2 (10 minutes plus response times)
SAMPLE 3 ... CHOICE 3 (15 minutes plus response times)
... total 30 minutes plus response times
But the task could potentially be run in a more time-efficient manner, also requiring the subject to memorize several samples at once:
SAMPLE 1 ...
SAMPLE 2 ...
SAMPLE 3 ...
CHOICE 3
CHOICE 2
CHOICE 1
... total 15 minutes plus response times
The ListDMS task implements a generic algorithm that takes a large set of "dumbbell"-shaped temporal objects:
SAMPLE-gap-CHOICE
or XXXXX----------------------XXXXXX
and schedules them to minimize the overall total time, without any of the "XXX" parts overlapping.
Several scheduling methods may be used, including
"stack"
XXXXXXX--------XXXXXXXXXX
XXXXX-----XXXXXX
"nest"
XXXXXXXX-------------------XXXXXXXXXX
XXXXX------XXXXXX
"overlap"
XXXXXXXX----------------XXXXXXXX
XXXXXXX----------------------XXXXXXXX
In what follows, "subnesting" means the following:
fully subnested
XXXXXXXX-------------------------------------XXXXXXXXXX
XXXXX---------XXXXXX
XXX---XXX
not fully subnested
XXXXXXXX-------------------------------------XXXXXXXXXX
XXXXX---------XXXXXX XXX---XXX
not fully subnested
XXXXXXXX-------------------------------------XXXXXXXXXX
XXXXX---------XXXXXX
XXX---------XXX
If you're not interested in how the scheduler works, skip the next few paragraphs.
"IN ADVANCE" SCHEDULING. The schedule is determined completely in advance. Therefore, we need to know how long each part of each trial's XXX-------XXXX structure is. The memory delay begins at the moment that the sample phase (Phase 1) ends - because that's when the stimulus vanishes, and the subject must begin to rely on its memory. Therefore, the scheduled "dumbbell", with its two "elements" to be scheduled, is made up as follows:
| • | first element length = maximum Phase 1 (sample phase) time (the scheduler takes into account whether lever initiation is being used, and whether the subject has to respond to Phase 1, and any reward time if Phase 1 is being rewarded, and so on) |
| • | gap length = memory delay MINUS first element length (because the memory delay could start almost immediately after Phase 1 begins, if the subject responds quickly, or right at the end, if it responds late). |
| • | second element length = maximum Phase 2 (choice phase) time PLUS maximum Phase 1 time (for the same reason as above) (the scheduler also takes into account the minimum intertrial time, and the maximum reward/punishment time). |
// scheduling in advance
// 1=phase2, .=memorydelay, 2=phase2, X=first/second scheduling element, -=scheduling gap
//
// 1111111..............222222222 long phase 1
// 1..............222222222 short phase 1
// XXXXXXX--------XXXXXXXXXXXXXXX elements and gap
"ON THE FLY" SCHEDULING. The schedule is drafted as above, creating a sequence of trials (and a draft but not quite a full schedule; see below). However, the program aims to use the entire memory delay as the "gap". Therefore:
| • | first element length = maximum Phase 1 time (as before) PLUS an "on-the-fly" safety margin of 50ms (to more than compensate for a potential couple of milliseconds of inaccuracy caused by recalculating on the fly and communicating changes to the server; in the source code, this is LISTDMS_ONTHEFLY_SAFETY_MARGIN); |
| • | gap length = memory delay MINUS any "phase 1 leftover" time (intertrial time and time spent rewarding Phase 1 - this is time that occurs within the memory delay, as the memory delay starts from the moment of responding in phase 1, but is not schedulable within the memory delay) MINUS LISTDMS_ONTHEFLY_SAFETY_MARGIN; |
| • | second element length = maximum Phase 2 time PLUS an "on-the-fly" safety margin of 50ms (LISTDMS_ONTHEFLY_SAFETY_MARGIN). |
Having drafted the schedule, the task then sets up the first trial. When that trial's phase 1 is complete, the program calculates the time saved (the difference between the actual first element length, and the scheduled maximum possible first element length). All subsequent trials are then brought forward by the time saved (if possible, i.e. if a scheduled Phase 2 doesn't prohibit some later trials from being brought forward). The next trial's start time is thus determined, and this trial is set up. (The timing of subsequent trials remains uncertain until we know the actual first element time for the trial that's coming.)
// scheduling on the fly
// 1111111..............222222222 long phase 1
// #
// 1..............222222222 short phase 1
// # # = during memory delay but not schedulable (e.g. reward, wait time)
// XXXXXXXX-------------XXXXXXXXX~ elements and gap (~ = safety margin)
In this scheduling system, overlaps cause a problem (because bringing forward all forthcoming trials might cause conflicts with existing schedule Phase 2 components with which they might clash). Therefore, "overlap" optimizations are disabled for on-the-fly scheduling.
A few parts of the conventional D(N)MTS task are incompatible with this process (such as specifying the session length - this now becomes a consequence purely of the trials scheduled). The "correction" phase is removed. The maximum time between trials is now a consequence of the trial schedule and cannot be specified manually. The sequence of trial delays is now determined by the scheduler, not by the user. There are slight modifications to the way that the number of distractors can progress (but only to the extent of making the task logically consistent). Otherwise, the ListDMS task implements all the options of the D(N)MTS task.
Configuring the task

| • | All the parameters are the same as the D(N)MTS task, with the exception of the following. |
| • | Maximum number of trials: REMOVED. |
| • | Maximum time: REMOVED. |
| • | "Try to avoid stimuli used in the last N trials": Stimuli for both phase 1 (sample) and phase 2 (choice) are assigned at the moment that Phase 1 begins. Therefore, "used in the last N trials" may include some trials for which Phase 1 has been presented, but Phase 2 is yet to be presented. Other than this quirk, the functionality is identical to the D(N)MTS task. |
| • | Time between trials: can specify the minimum only, not the maximum. Try to make this as short as possible, to keep the overall session time down and to allow more space to squeeze in trials interleaved among each other. |
| • | Delays are specified in a simple list, with a list multiplier (how many copies of the list are to be used?). This determines the number of trials, and the schedule. For example, if you have 4 delays in the list, and use 4 copies of the list, you will get 16 trials. You can enter the same delay into the list several times, if you wish. Delays can be zero. As in the D(N)MTS task, setting a delay as negative means a zero delay with the sample stimulus shown alongside the choice stimuli in Phase 2 ("simultaneous" variant). |
| • | Optionally, you can schedule in clusters. Choose "Schedule each copy of the list independently (and identically) then concatenate". If you do this, one copy of the list is scheduled, and then n copies of the schedule are run back-to-back. This may be useful, but isn't optimally efficient. By default (with this option unticked), the whole multiple-copy list is scheduled as one entity. This may give a more complex schedule but a more efficient one. (If you only use one copy of the list, obviously this tickbox does nothing.) |
| • | Choose schedule in advance or schedule on the fly. In-advance scheduling gives a schedule that will be adhered to strictly in terms of trial start times. On-the-fly scheduling is more efficient; the order of the trials is fixed, but the actual start times are altered slightly, "live", to allow the entire memory delay to be filled with other trials (described above). |
| • | Choose the scheduling strategy: do you want to minimize overall schedule duration (in which the strategies used, internally termed Sizist and Methodologist, may or may not produce full subnesting) or to prioritize subnesting (described above) over schedule length? |
| • | You can also force the disabling of nest and overlap optimization methods; overlap optimizations are in any case disabled for on-the-fly scheduling (as described above), and you cannot disable nesting if you specify the "prioritize subnesting" scheduling strategy. |
| • | Once you've specified the delays and the multiplier, you can have a look at the schedule that'll be used: click View Schedule. More detail is given below. |
| • | The options for the number of distractors are the same as the D(N)MTS task, except for a caveat about two options: "Move to the next #distractors every Y trials" and "Move to the next #distractors when Y of last 20 trials were correct". The need for a change is obvious: since sample and choice phases may now occur in novel sequences. Since the number of distractors is assigned internally when Phase 1 begins, these options are changed as follows. (1) The "Move to the next #distractors every Y trials" option works as usual, except that the sequence of distractors is an orderly progression from the point of view of the Phase 2 elements (and therefore not necessarily of the Phase 1 elements) even if that Phase 2 is never presented (because the subject fails Phase 1). (2) The "Move to the next #distractors when Y of last 20 trials were correct" option refers to the last 20 choice phases (Phase 2s), at the time that the trial's Phase 1 begins; this clearly isn't quite as sensible as in the D(N)MTS task and it is probably best not used. |
| • | The option to repeat all or parts of a trial (give a correction trial) is removed, as this unpredictability would mess up the scheduling. |
| • | The option to reward Phase 1 performance is removed, as this makes the timing of the memory delay and scheduling other trials harder. |
More on the schedules
A sample schedule looks like this:
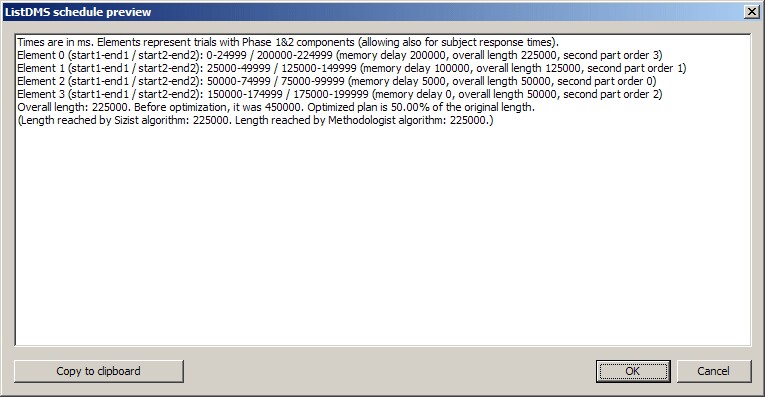
This particular example is for 1 copy of a list with delays 0, 5, 100, 200 sec (with response time limits, reward times, etc., set in the rest of the task parameters, as described above, and in the General Parameters). The scheduler has done this:
0 25 50 75 100 125 150 175 200
SAMPLE0.................................................CHOICE0 (this will be TRIAL 0)
.......SAMPLE1.....................CHOICE1 (this will be TRIAL 1)
..............SAMPLE2CHOICE2 (this will be TRIAL 2)
..........................................SAMPLE3CHOICE3 (this will be TRIAL 3)
Note also that extra time is allowed for response times, reward, etc.; therefore, trials with short memory delays appear to have no gap scheduled (all this means is that the potential variability in subjects' responses means that there is no gap into which another trial, or component of a trial, could potentially be scheduled).
There appears to be no gap between, for example, SAMPLE0 and SAMPLE1 - but the scheduler has already incorporated the "minimum time between trials" into the end of each segment, so this gap will be present (from the scheduler's point of view, SAMPLE0 ends when the sample is over, and then any time that the sample could have taken if the subject were a bit slower to respond [if you're making your subject respond to sample phases], plus the minimum time between trials, and any reward time, etc.).
You can take a copy of the schedule for the clipboard if you wish (though, of course, it is also saved in the results textfile, and equivalent information is saved to the results database).
As of 8 Mar 2010, the schedule also reports the size from the Subnest algorithm, and whether the resulting final schedule is fully subnested or not.
In the "Chronological Order" section of the results (e.g. the ListDMS_ChronologicalOrder table in the database), this structure will appear as follows, if the subject responds to all trials:
SegmentNumber,SegmentStartTimeMs,Trial,Phase
0,...,0,1
1,...,1,1
2,...,2,1
3,...,2,2
4,...,1,2
5,...,3,1
6,...,3,2
7,...,0,2
In the trial-based results (e.g. the ListDMS_Results table in the database), all trials appear, even if they were not given; look for the Phase1Given and Phase2Given fields to see if they were actually delivered. Look at the OrderInPhase2Sequence field to quickly determine the sequence of Phase 2 components (this is the number shown as "second part order" in the schedule description shown above). Phase 1 components are given in the order that the trials appear in the results.